Advanced LLM AI models vs A Simple Question
I wanted to find out what the current state-of-art of the current largest LLM models is. There are great and many standardised ways to test the quality of any LLM model, but I wanted an easier way.
I stumbled upon a seemingly simple logic test question, which I fed directly into OpenAI, Co-Pilot, Gemini, Inflection AI, Mistral AI and Anthropic.
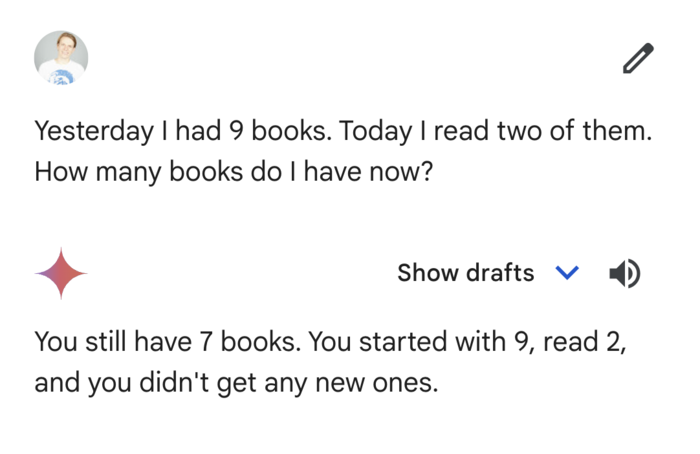
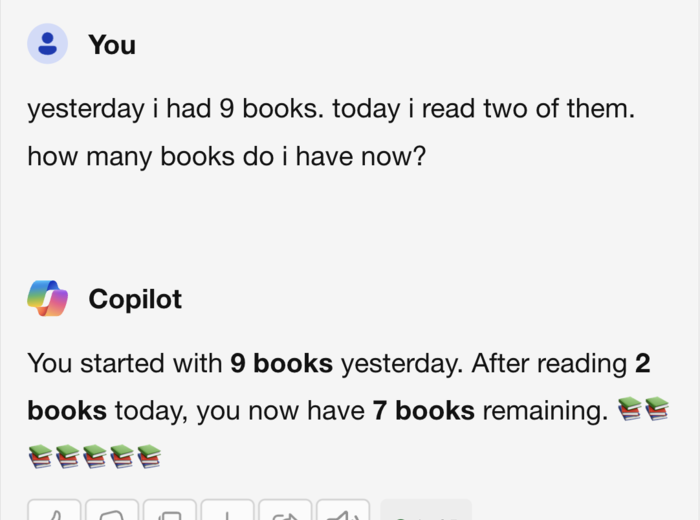
Yesterday I had 9 books. Today I read two of them. How many books do I have now?
I am sure, you, as a human see the gotcha and will answer the question correctly. But how will our LLM AI models fare?
Lets start with one of the oldest companies, author of the original Transformer paper and valued over $1 trillion, Google's Gemini Advanced (aka Ultra 1.0) model, launched February 2024:
Second with Anthropic's Claude Opus launched March 2024. Tested best compared to any other competing models according to their press release:

Next we have Microsoft Bing with Co-pilot, enabled by default if you search in Windows or Bing. To my knowledge this is powered by OpenAI's GPT 3.5, and can't be upgraded for users:
Luckily, we also have some LLM's that got the answer right:
Europe's Mistral AI, with the Large model launched February 2024:

Inflection AI after their 1.3B funding and their 2.5 model also launched March 2024, accessed via their pi.ai assistent:

And although the GPT 3.5 model failed (see Bing's co-pilot), OpenAI's GPT 4 got it right.

Can't wait to see the test results in a few months. If the AI is lucky, it will train on the answer provided by the correct models.

